I have been a BDD practitioner for a few years, a combination of self-learning and attending various user groups and getting useful feedback from my peers. BDD is something you pick up gradually and gets better with practice. My personal experience when starting to use BDD was that it can be a form of information overload because one is not sure where to start. With newcomers, sometimes the focus is on the tools rather than the extracting and understand the actual behaviour of the business. Some people think they've practised BDD if they just write scenarios and automate their examples, a tick box exercise. But BDD is and should be larger than that.
I was fortunate to be asked to peer review a set of online training videos from the Cucumber School, the team who originally created Cucumber. The course assumes no prior knowledge in BDD concepts or the use of Cucumber. Every video has a range of exercises that you can perform after watching to reinforce your learning. This is great as it means that the videos are not a dry exercise in memory retention but rather an impetus for self-learning.
I was gratified to see that the initial lesson were geared towards fleshing out behaviour via conversations or examples rather than diving straight into the tool. This is achieved by the need for distinct user roles in defining and refining those examples.

A team is usually built of different disciplines such as developers, testers and a business representative such as a product owner. What was hammered home during the lessons was the need for continual collaboration and communication between all team members so that the specifications constructed were effective and garnered common understanding.
An exploration of the Gherkin syntax was covered. Gherkin is a business readable DSL that describes the behaviour of your software without detailing its implementation. You can think of this as a form of standardization in how your scenarios should be constructed. Cucumber School gave an excellent explanation on Gherkin and how to tailor scenarios effectively.

Later lessons then dived into the actual Cucumber tool itself, right from setting up the IDE, generating skeleton code from scenarios and then fleshing out the implementation. This was all performed in an iterative manner. I found this extremely beneficial because it demonstrated how to build up the executable part of a specification gradually. The code was incrementally built to support the individual steps of a Gherkin scenario. The re-use of step code across similar steps was a fundamental point through the judicious use of regular expressions. Again no former knowledge of regular expressions was expected. A beginner could still pick up the salient points and write their own expressions by the end of the lesson. Emphasis was also placed on the readability of scenarios so that they were kept relevant to the business and their intent was clear.
When devising steps, another point conveyed that the steps should really be a thin veneer across a domain model. This is important because the domain model should be able to exist independently of the BDD framework. TDD was heavily enforced to flesh out the model that the scenarios suggested. Constant refinement of scenarios and unit tests was encouraged. A great point was made about listening to tests because they were a reflection on how well the domain was understood and also on how well that domain or scenario could be tested. Removal of whole scenarios was also encouraged if those scenarios no longer had any value. A scenario may have been written which in retrospect duplicated or was a simply a generalization of another scenario which captured that behavior more succinctly. In that case, the scenario should be pruned. Refactoring of code but also refactoring of the scenarios themselves was a salient aspect of the training. For instance, some scenarios were better described with the use of tables. This was all to keep the scenarios understandable and focused. Another point that was driven home was to strive to get the scenarios described at the right level of detail. Enough for the feature to be adequately described but not so little that the scenario became too vague or not too much detail so that the implementation did seep into the scenario.
A practice which I intend to follow is Example Mapping. This is a great tool during the inception phase of a project when one is trying to understand the problem to solve whilst also taking note of those questions we still have to answer. Example Mapping is a technique to break stories into rules and examples. This is a great example of Deliberate Discovery where we try to get feedback for the application we're about to build before we actually write any code. By focusing on examples, we get a feel on how the application will behave before its existence.

I like that a holistic view of development was portrayed in the sense that BDD and TDD were not considered disparate, but practices to be followed at different levels of granularity. A great phrase that resonated with me was that BDD enforced outside-in development.
BDD ensures you're building the right thing, but TDD ensures you're building the thing right.

Also emphasized that BDD encourages different types of testing should be covered at different levels. For instance, there should be a plethora of TDD tests at the bottom of the scale, then system or integration tests to tie the domains together with BDD or scenario level tests above that. At the top should exist exploratory testing. What sometimes happens is that although automation is in place, there is still a substantial amount manual testing undertook, which is both laborious, slow to complete and error prone.

BDD encourages that the higher up the pyramid one goes, the less testing there should be. All of the testing permutations happen lower down so that as we rise, although the tests become fewer, they become more important.

The final lessons touched upon testing the domain model from a web-front-end. Automation was achieved via the use of Selenium. I'm not a front-end developer, but the example shown was easily understandable and a great base to build upon for future front-end testing.
It was great to see the hexagonal design pattern being promoted to facilitate easy swapping of testing the domain directly or from the front-end. This pattern also known as a port and adapters allows one to separate the core business logic from anything that touches the outside world such as front-ends or databases. This enables the domain to be tested either directly or from a browser. It was a great example of front end testing but also defining scenarios so that the domain was separate from any front-end concerns.
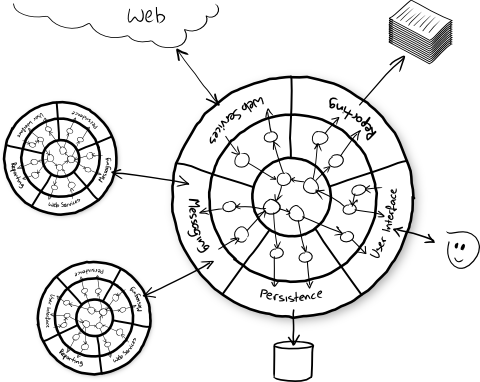
(Reprinted from Nat Pryce's Ports and Adapters Architecture)
As I proceeded through the lessons, any questions I had on BDD on testing or the right way to approach devising a domain model were answered by later lessons. This was a great way to learn and for those points to stick in the mind.
A lot of people still think BDD is a tool and is only about testing. For a long time, I was one of those people too. I believe BDD is still poorly understood and frequently misappropriated. But following the Cucumber School lessons, I think a lot of the misnomers of BDD will be eradicated. At the end of the course I feel I've gained several approaches to finding solutions to problems in new ways.
So in conclusion,
- The videos and related exercises are excellent in describing the benefits of developing software following a BDD approach
- I liked that the modus operandi was to adopt a reactive approach rather than trying to get everything correct the first time round. Recognizing shortcomings in scenarios or code and test smells led to feedback loops in which those were corrected later on. I think this was a great point to take away and remember.
- I liked how BDD was presented as complimentary to other practices or development techniques such as TDD or DDD.
- The lessons are very good for newcomers but experienced practitioners will also find useful information. I've certainly learnt some practices I wasn't aware of, which I'll carry into my daily work. The series of lessons from Cucumber School come highly recommended.
